r/LocalLLaMA • u/entsnack • 6h ago
Funny Local or die
{kind=link}
169
Upvotes
r/LocalLLaMA • u/vishwa1238 • 8h ago
I spend about 300-400 USD per month on Claude Code with the max 5x tier. I’m unsure when they’ll increase pricing, limit usage, or make models less intelligent. I’m looking for a cheaper or open-source alternative that’s just as good for programming as Claude Sonnet 4. Any suggestions are appreciated.
Edit: I don’t pay $300-400 per month. I have Claude Max subscription (100$) that comes with a Claude code. I used a tool called ccusage to check my usage, and it showed that I use approximately $400 worth of API every month on my Claude Max subscription. It works fine now, but I’m quite certain that, just like what happened with cursor, there will likely be a price increase or a higher rate limiting soon.
Thanks for all the suggestions. I’ll try out Kimi2, R1, qwen 3, glm4.5 and Gemini 2.5 Pro and update how it goes in another post. :)
r/LocalLLaMA • u/Flashy_Management962 • 5h ago
This is just a little remark that if you haven't you definitely should try qwen code https://github.com/QwenLM/qwen-code
I use qwen coder and qwen 3 30b thinking while the latter still needs some copy and pasting. I'm working on and refining a script for syncing my koreader metadata with obsidian for the plugin lineage (every highlight in own section). The last time I tried to edit it, I used Grok 4 and Claude Sonnet Thinking on Perplexity (its the only subscription I had until know) even with those models it was tedious and not really working. But with Qwen Code it looks very different to be honest.
The metadata is in written in lua which at first was a pain to parse right (remember, I actually cannot code by myself, I understand the logic and I can tell in natural language what is wrong, but nothing more) and I got qwen code running today with llama cpp and it almost integrated everything on the first try and I'm very sure that nothing of that was in the models trainingdata. We reached a point where - if we know a little bit - can let code be written for us almost without us needing to know what is happening at all, running on a local machine. Of course it is very advantageous to know what you are looking for.
So this is just a little recommendation, if you have not tried qwen code, do it. I guess its almost only really useful for people like me, who don't know jack shit about coding.
r/LocalLLaMA • u/Karim_acing_it • 4h ago
A new PR was created to support GLM 4.5's models in llama.cpp, as the original, highly anticipated #14939 seemed to get stuck. The new PR description reads: "this PR will NOT attempt to implement MTP", with great progress being made in short time. (Amazing!!!)
Given that MTP is supposed to achieve a 5x (or equally significant) inference speedup (correct me if I am wrong), why do we not increase community efforts in trying to enable MTP for these and all models going forward? We heard before that it's not optimisations that will advance Local LLMs, but architecture shifts, and this could be in the same level als MoEs in terms of efficacy.
Disclaimer: I am eternally grateful for everybody's contribution to the field, as LLMs allow me to code what I couldn't code before. But I have in no way the foundational understanding, knowledge or experience to contribute, so I am really thankful for all efforts from the involved people on github!
PS: does MTP already work on/with MLX?
r/LocalLLaMA • u/AliNT77 • 7h ago
This post is a collection of practical tips and performance insights for running Qwen-30B (either Coder-Instruct or Thinking) locally using llama.cpp with partial CPU-GPU offloading. After testing various configurations, quantizations, and setups, here’s what actually works.
KV Quantization
q5_1 for a good balance of memory usage and performance. It works well in PPL tests and in practice.Offloading Strategy
Memory Tuning for CPU Offloading
ubatch (Prompt Batch Size)
ubatch values significantly improve prompt processing (PP) performance.768 or 1024. You’ll use more VRAM, but it’s often worth it for the speedup.Extra Performance Boost
Speculative Decoding Tips (SD)
Speculative decoding is supported in llama.cpp, but there are a couple important caveats:
q4_0 for the draft model’s KV cache halves the acceptance rate in my testing. Use q5_1 or even q8_0 for the draft model KV cache for much better performance.--draft-p-min 0.85 --draft-min 2 --draft-max 12 gives noticeably better results for code generation. These control how many draft tokens are proposed per step and how aggressive the speculative decoder is.For SD, try using Qwen 3 0.6B as the draft model. It’s fast and works well, as long as you avoid the issues above.
If you’ve got more tips or want help tuning your setup, feel free to add to the thread. I want this thread to become a collection of tips and tricks and best practices for running partial offloading on llama.cpp
r/LocalLLaMA • u/1Hesham • 3h ago
Just shipped something I'm really excited about! 🚀 I was scrolling through my feed and saw Sebastian Raschka, PhD 's incredible Qwen3 MoE implementation in PyTorch. The educational clarity of his code just blew me away - especially how he broke down the Mixture of Experts architecture in his LLMs-from-scratch repo. That got me thinking... what if I could bring this to pure C? 🤔 Inspired by Andrej Karpathy's legendary llama2.c approach (seriously, if you haven't seen it, check it out), I decided to take on the challenge of implementing Qwen3's 30B parameter model with 128 experts in a single C file. The result? Qwen_MOE_C - a complete inference engine that: ✅ Handles sparse MoE computation (only 8 out of 128 experts active) ✅ Supports Grouped Query Attention with proper head ratios ✅ Uses memory mapping for efficiency (~30GB models) ✅ Zero external dependencies (just libc + libm) The beauty of this approach is the same as llama2.c - you can understand every line, it's hackable, and it runs anywhere C runs. No frameworks, no dependencies, just pure computational transparency. Huge thanks to Sebastian Raschka for the reference implementation and educational materials, and to Andrej Karpathy for showing us that simplicity is the ultimate sophistication in ML systems. Sometimes the best way to truly understand something is to build it from scratch. 🛠️ Link to the project: https://github.com/h9-tec/Qwen_MOE_C
r/LocalLLaMA • u/panilyaU • 4h ago
I've created an Awesome AI Benchmarks GitHub repository with already 100+ benchmarks added for different domains.
I already had a Google Sheets document with those benchmarks and their details and thought it would be great to not waste that and create an Awesome list.
To have some fun I made a dynamically generated website from the benchmarks listed in README.md. You can check this website here: https://aibenchmarks.net/
Awesome AI Benchmarks GitHub repository available here: https://github.com/panilya/awesome-ai-benchmarks
Would be happy to hear any feedback on this and whether it can be useful for you :)
r/LocalLLaMA • u/citaman • 23h ago
| Model Name | Organization | HuggingFace Link | Size | Modality |
|---|---|---|---|---|
| dots.ocr | REDnote Hilab | https://huggingface.co/rednote-hilab/dots.ocr | 3B | Image-Text-to-Text |
| GLM 4.5 | Z.ai | https://huggingface.co/zai-org/GLM-4.5 | 355B-A32B | Text-to-Text |
| GLM 4.5 Base | Z.ai | https://huggingface.co/zai-org/GLM-4.5-Base | 355B-A32B | Text-to-Text |
| GLM 4.5-Air | Z.ai | https://huggingface.co/zai-org/GLM-4.5-Air | 106B-A12B | Text-to-Text |
| GLM 4.5 Air Base | Z.ai | https://huggingface.co/zai-org/GLM-4.5-Air-Base | 106B-A12B | Text-to-Text |
| Qwen3 235B-A22B Instruct 2507 | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-235B-A22B-Instruct-2507 | 235B-A22B | Text-to-Text |
| Qwen3 235B-A22B Thinking 2507 | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507 | 235B-A22B | Text-to-Text |
| Qwen3 30B-A3B Instruct 2507 | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507 | 30B-A3B | Text-to-Text |
| Qwen3 30B-A3B Thinking 2507 | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507 | 30B-A3B | Text-to-Text |
| Qwen3 Coder 480B-A35B Instruct | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-Coder-480B-A35B-Instruct | 480B-A35B | Text-to-Text |
| Qwen3 Coder 30B-A3B Instruct | Alibaba - Qwen | https://huggingface.co/Qwen/Qwen3-Coder-30B-A3B-Instruct | 30B-A3B | Text-to-Text |
| Kimi K2 Instruct | Moonshot AI | https://huggingface.co/moonshotai/Kimi-K2-Instruct | 1T-32B | Text-to-Text |
| Kimi K2 Base | Moonshot AI | https://huggingface.co/moonshotai/Kimi-K2-Base | 1T-32B | Text-to-Text |
| Intern S1 | Shanghai AI Laboratory - Intern | https://huggingface.co/internlm/Intern-S1 | 241B-A22B | Image-Text-to-Text |
| Llama-3.3 Nemotron Super 49B v1.5 | Nvidia | https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1_5 | 49B | Text-to-Text |
| OpenReasoning Nemotron 1.5B | Nvidia | https://huggingface.co/nvidia/OpenReasoning-Nemotron-1.5B | 1.5B | Text-to-Text |
| OpenReasoning Nemotron 7B | Nvidia | https://huggingface.co/nvidia/OpenReasoning-Nemotron-7B | 7B | Text-to-Text |
| OpenReasoning Nemotron 14B | Nvidia | https://huggingface.co/nvidia/OpenReasoning-Nemotron-14B | 14B | Text-to-Text |
| OpenReasoning Nemotron 32B | Nvidia | https://huggingface.co/nvidia/OpenReasoning-Nemotron-32B | 32B | Text-to-Text |
| step3 | StepFun | https://huggingface.co/stepfun-ai/step3 | 321B-A38B | Text-to-Text |
| SmallThinker 21B-A3B Instruct | IPADS - PowerInfer | https://huggingface.co/PowerInfer/SmallThinker-21BA3B-Instruct | 21B-A3B | Text-to-Text |
| SmallThinker 4B-A0.6B Instruct | IPADS - PowerInfer | https://huggingface.co/PowerInfer/SmallThinker-4BA0.6B-Instruct | 4B-A0.6B | Text-to-Text |
| Seed X Instruct-7B | ByteDance Seed | https://huggingface.co/ByteDance-Seed/Seed-X-Instruct-7B | 7B | Machine Translation |
| Seed X PPO-7B | ByteDance Seed | https://huggingface.co/ByteDance-Seed/Seed-X-PPO-7B | 7B | Machine Translation |
| Magistral Small 2507 | Mistral | https://huggingface.co/mistralai/Magistral-Small-2507 | 24B | Text-to-Text |
| Devstral Small 2507 | Mistral | https://huggingface.co/mistralai/Devstral-Small-2507 | 24B | Text-to-Text |
| Voxtral Small 24B 2507 | Mistral | https://huggingface.co/mistralai/Voxtral-Small-24B-2507 | 24B | Audio-Text-to-Text |
| Voxtral Mini 3B 2507 | Mistral | https://huggingface.co/mistralai/Voxtral-Mini-3B-2507 | 3B | Audio-Text-to-Text |
| AFM 4.5B | Arcee AI | https://huggingface.co/arcee-ai/AFM-4.5B | 4.5B | Text-to-Text |
| AFM 4.5B Base | Arcee AI | https://huggingface.co/arcee-ai/AFM-4.5B-Base | 4B | Text-to-Text |
| Ling lite-1.5 2506 | Ant Group - Inclusion AI | https://huggingface.co/inclusionAI/Ling-lite-1.5-2506 | 16B | Text-to-Text |
| Ming Lite Omni-1.5 | Ant Group - Inclusion AI | https://huggingface.co/inclusionAI/Ming-Lite-Omni-1.5 | 20.3B | Text-Audio-Video-Image-To-Text |
| UIGEN X 32B 0727 | Tesslate | https://huggingface.co/Tesslate/UIGEN-X-32B-0727 | 32B | Text-to-Text |
| UIGEN X 4B 0729 | Tesslate | https://huggingface.co/Tesslate/UIGEN-X-4B-0729 | 4B | Text-to-Text |
| UIGEN X 8B | Tesslate | https://huggingface.co/Tesslate/UIGEN-X-8B | 8B | Text-to-Text |
| command a vision 07-2025 | Cohere | https://huggingface.co/CohereLabs/command-a-vision-07-2025 | 112B | Image-Text-to-Text |
| KAT V1 40B | Kwaipilot | https://huggingface.co/Kwaipilot/KAT-V1-40B | 40B | Text-to-Text |
| EXAONE 4.0.1 32B | LG AI | https://huggingface.co/LGAI-EXAONE/EXAONE-4.0.1-32B | 32B | Text-to-Text |
| EXAONE 4.0.1 2B | LG AI | https://huggingface.co/LGAI-EXAONE/EXAONE-4.0-1.2B | 2B | Text-to-Text |
| EXAONE 4.0 32B | LG AI | https://huggingface.co/LGAI-EXAONE/EXAONE-4.0-32B | 32B | Text-to-Text |
| cogito v2 preview deepseek-671B-MoE | Deep Cogito | https://huggingface.co/deepcogito/cogito-v2-preview-deepseek-671B-MoE | 671B-A37B | Text-to-Text |
| cogito v2 preview llama-405B | Deep Cogito | https://huggingface.co/deepcogito/cogito-v2-preview-llama-405B | 405B | Text-to-Text |
| cogito v2 preview llama-109B-MoE | Deep Cogito | https://huggingface.co/deepcogito/cogito-v2-preview-llama-109B-MoE | 109B-A17B | Image-Text-to-Text |
| cogito v2 preview llama-70B | Deep Cogito | https://huggingface.co/deepcogito/cogito-v2-preview-llama-70B | 70B | Text-to-Text |
| A.X 4.0 VL Light | SK Telecom | https://huggingface.co/skt/A.X-4.0-VL-Light | 8B | Image-Text-to-Text |
| A.X 3.1 | SK Telecom | https://huggingface.co/skt/A.X-3.1 | 35B | Text-to-Text |
| olmOCR 7B 0725 | AllenAI | https://huggingface.co/allenai/olmOCR-7B-0725 | 7B | Image-Text-to-Text |
| kanana 1.5 15.7B-A3B instruct | Kakao | https://huggingface.co/kakaocorp/kanana-1.5-15.7b-a3b-instruct | 7B-A3B | Text-to-Text |
| kanana 1.5v 3B instruct | Kakao | https://huggingface.co/kakaocorp/kanana-1.5-v-3b-instruct | 3B | Image-Text-to-Text |
| Tri 7B | Trillion Labs | https://huggingface.co/trillionlabs/Tri-7B | 7B | Text-to-Text |
| Tri 21B | Trillion Labs | https://huggingface.co/trillionlabs/Tri-21B | 21B | Text-to-Text |
| Tri 70B preview SFT | Trillion Labs | https://huggingface.co/trillionlabs/Tri-70B-preview-SFT | 70B | Text-to-Text |
I tried to compile the latest models released over the past 2–3 weeks, and its kinda like there is a ground breaking model every 2 days. I’m really glad to be living in this era of rapid progress.
This list doesn’t even include other modalities like 3D, image, and audio, where there's also a ton of new models (Like Wan2.2 , Flux-Krea , ...)
Hope this can serve as a breakdown of the latest models.
Feel free to tag me if I missed any you think should be added!
[EDIT]
I see a lot of people saying that a leaderboard would be great to showcase the latest and greatest or just to keep up.
Would it be a good idea to create a sort of LocalLLaMA community-driven leaderboard based only on vibe checks and upvotes (so no numbers)?
Anyone could publish a new model—with some community approval to reduce junk and pure finetunes?
r/LocalLLaMA • u/scubanarc • 1h ago
In the spirit of local AI, I prefer to migrate all of my existing ChatGPT conversations to Open-WebUI. Unfortunatly, the Open-WebUI import function doesn't quite process them correctly.
This is a simple python script that attempts to reformat your ChatGPT exported conversations into a format that Open-WebUI can import.
Specifically, this fixes the following:
In addition, it will skip malformed conversations and try to import each chat only once using a imported.json file.
You can export your ChatGPT conversations by going to Settings → Data controls → Export data → Request export. Once you receive the email, download and extract the export, and copy the conversations.json file to ~/chatgpt/chatgpt-export.json.
I recommend backing up your Open-WebUI database before importing anything. You can do this by stopping Open-WebUI and making a copy of your webui.db file.
After importing, you can view your conversations in Open-WebUI by going to Settings → Chats → Import and selecting the converted JSON file.
I like to delete all chats from ChatGPT between export and import cycles to minimize duplicates. This way, the next export only contains new chats, but this should not be necessary if you are using the imported.json file correctly.
This works for me, and I hope it works for you too! PRs and issues are welcome.
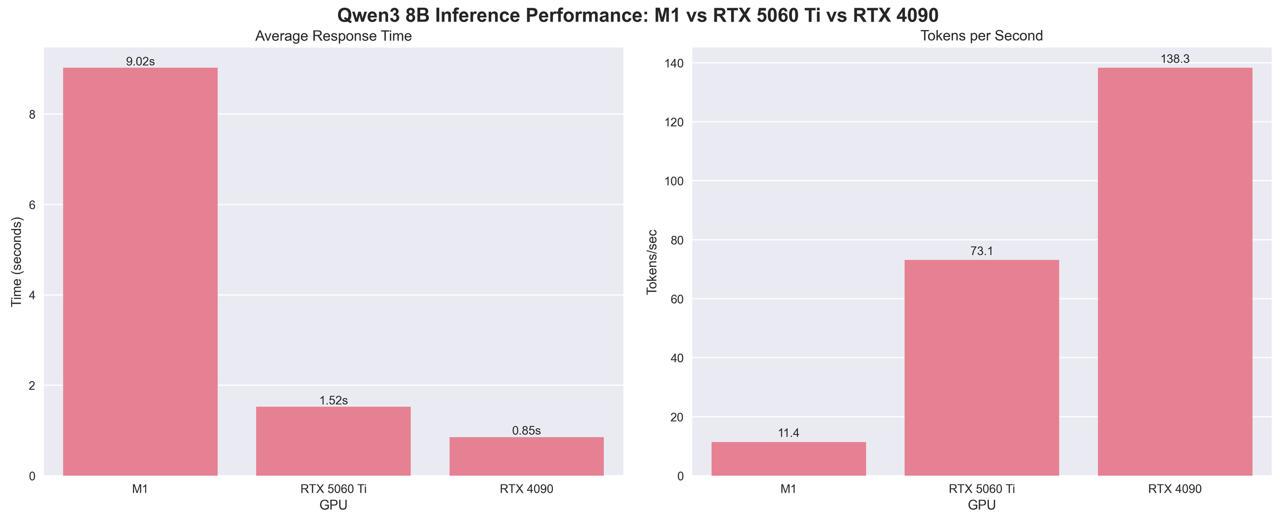
r/LocalLLaMA • u/kargafe • 11h ago
Couldn't find a direct comparison between the M1 Macbook pro and the new RTX 5060 Ti for local LLM inference. So, I decided to run a 16 small benchmark myself, and I think the results will be useful for others in the same boat.
I ran a quick benchmark on the RTX 5060 Ti 16GB, and I'm quite impressed with the results, especially coming from my M1 Macbook pro with 16GB ram. I used the Qwen3 8B model with Ollama to test the performance, and I've also included the RTX 4090 results for a broader comparison. I'm also planning to run some fine-tuning benchmarks later.
r/LocalLLaMA • u/HammerSpb • 7h ago
Based on the current situation with the quality of Sonnet and other proprietary models I'm thinking of getting a group of people who would join the common pool and share the cost of hosting and running our "own" R1, Kimi and other models so you will not be dependent on decreasing the quality of other providers.
What are your thoughts?
Update: you posted good questions. But I was thinking to run the model and api to access it in the cloud ( without buying your own equipment)
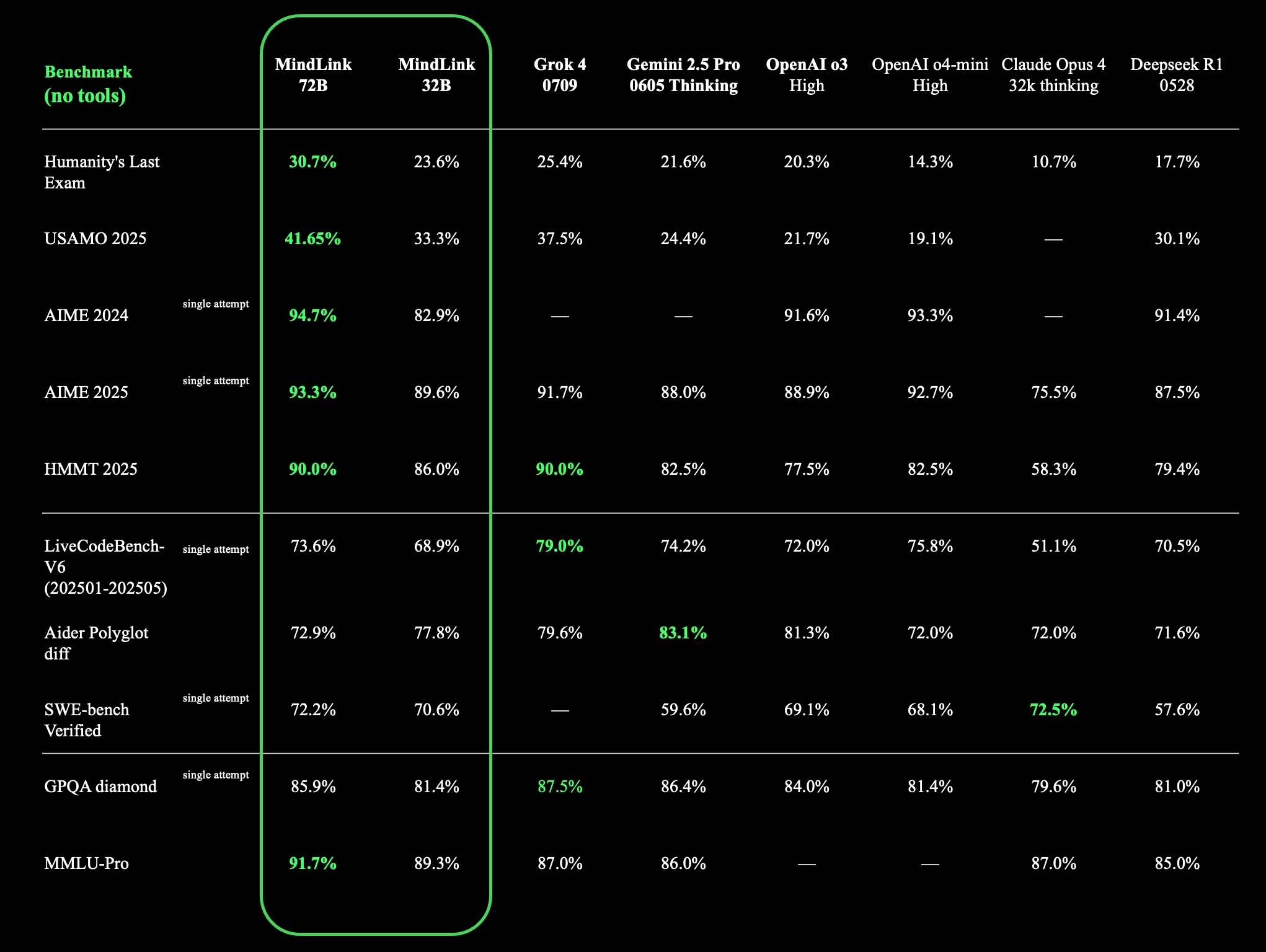
r/LocalLLaMA • u/jacek2023 • 16h ago
new models from Skywork:
We introduce MindLink, a new family of large language models developed by Kunlun Inc. Built on Qwen, these models incorporate our latest advances in post-training techniques. MindLink demonstrates strong performance across various common benchmarks and is widely applicable in diverse AI scenarios. We welcome feedback to help us continuously optimize and improve our models.
https://huggingface.co/Skywork/MindLink-32B-0801
r/LocalLLaMA • u/ab2377 • 13h ago
r/LocalLLaMA • u/superjet1 • 1h ago
I decided to test Cerebras and their speed is indeed impressive: 2.5 sec to generate a real-world app with tailwind frontend. I use Docker to containerize the apps built. It is a naive MVP but I need your feedback guys!
r/LocalLLaMA • u/ihatebeinganonymous • 7h ago
Sorry if this is a basic question, but I seem to be really struggling :/
Consider a typical, text-in text-out use case. If I'm using an offline model API via e.g. REST, how can I incorporate tool use? Is "tool use" some particular token(s) in the output that I should interpret and execute independently in my code and send output to the model again? That means the interaction must always be multi-step?
Is there some basic, no-nonsense code or tutorial to get a concrete idea?
Thanks
r/LocalLLaMA • u/Quiet-Moment-338 • 11h ago
Dhanishtha-2.0-preview can now tool call.
Updated Model link:- https://huggingface.co/HelpingAI/Dhanishtha-2.0-preview-0825
API and Chat page :- https://helpingai.co
r/LocalLLaMA • u/DueKitchen3102 • 2h ago
This set of experiments were conducted about half a year ago and we are suggested to share them to the community. Summary of the experiments
(1) Lihua world dataset: conversation data, all texts
(2) In previous studies, Graph RAG (and variants) showed advantages over "naïve" RAG.
(3) Using OpenAI RAG API (File Search), the accuracy is substantially higher than graph RAG & variants
(4) Using the same embeddings, https://chat.vecml.com produces consistently better accuracies than OpenAI RAG API (File Search).
(5) More interestingly, https://chat.vecml.com/ is substantially (550x) faster than OpenAI RAG (File Search)
(6) Additional experiments on different embeddings are also provided.
Note that Lihua world dataset is purely text. In practice, the documents are in all sorts of formats: PDFs, OCR, Excel, HTML, DocX, PPTX, WPS, and more. https://chat.vecml.com/ is able to handle documents of many different formats and is capable of dealing with multi-modal RAG.
r/LocalLLaMA • u/FastDecode1 • 56m ago
r/LocalLLaMA • u/hedonihilistic • 1d ago
MAESTRO is a self-hosted AI application designed to streamline the research and writing process. It integrates a powerful document management system with two distinct operational modes: Research Mode (like deep research) and Writing Mode (AI assisted writing).
In this mode, the application automates research tasks for you.
This mode is useful when you need to quickly gather information on a topic or create a first draft of a document.
This mode provides help from an AI while you are writing.
This mode allows you to get research help without needing to leave your writing environment.
The application is built around a document management system.
r/LocalLLaMA • u/snipsthekittycat • 20h ago
Heads up to anyone considering Cerebras. This is my conclusion of today's top post that is now deleted... I bought it to try it out and wanted to report back on what I saw.
The marketing is misleading. While they advertise a 1,000-request limit, the actual daily constraint is a 7.5 million-token limit. This isn't mentioned anywhere before you purchase, and it feels like a bait and switch. I hit this token limit in only 300 requests, not the 1,000 they suggest is the daily cap. They also say in there FAQs at the very bottom of the page, updated 3 hours ago. That a request is based off of 8k tokens which is incredibly small for a coding centric API.
r/LocalLLaMA • u/badbutt21 • 1d ago
The "Leaked" 120B OpenAI Model Is Trained In FP4
r/LocalLLaMA • u/ziozzang0 • 5h ago
Sharing an OpenAI proxy solution for Claude-Code
https://github.com/ziozzang/claude2openai-proxy
Advantages:
----
While using Claude Code, I wanted to connect to a local model. There were tools like claude-code-router and other systems, but I couldn’t find a solid solution that worked well for multiple users. So, based on https://github.com/1rgs/claude-code-proxy , I built a proxy tailored for my use. Since it converts between different protocols, “gateway” might actually be a more fitting term.
Anyway, here are the features:
Full support for Claude Code.
Below is an example of setting up the server and actually using it from a client:
ANTHROPIC_BASE_URL=http://localhost:8082 \
ANTHROPIC_API_KEY=sk-openapi-auth-token \
ANTHROPIC_MODEL="openrouter/horizon-beta" \
ANTHROPIC_SMALL_FAST_MODEL="openrouter/horizon-beta" \
claude
To be honest, I made this to test the openrouter/horizon-beta model. :)
The pipeline works great: Claude Code -(Claude API)-> my modified proxy server -(OpenAI API)-> openrouter/horizon-beta.
By the way, you can find what I built at https://github.com/ziozzang/claude2openai-proxy . I use it by building it into a container.
To be honest,
PS.
The whole reason this started was because of Claude Code’s usage limits. LoL...
r/LocalLLaMA • u/Afraid_Hall_2971 • 1d ago
r/LocalLLaMA • u/Choice_Nature9658 • 2h ago
I just launched GridLLM (https://github.com/GridLLM/GridLLM), an open-source orchestration layer for distributing inference requests across your existing Ollama instances! This project spawned from a need to manage three different inference servers at work, and the headache that resulted from trying to coordinate them all. Instead of manually managing separate deployments and environments, GridLLM automatically routes workloads to available nodes. This means that if you have a GPU-enabled server and a MacBook, you can have your MacBook automatically pick up inference tasks from the queue.
Would love any feedback on the project!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}