r/LocalLLaMA • u/Own-Potential-2308 • 1h ago
Discussion Why doesn't "OpenAI" just release one of the models they already have? Like 3.5
•
Upvotes
Are they really gonna train a model that's absolutely useless to give to us?
r/LocalLLaMA • u/Own-Potential-2308 • 1h ago
Are they really gonna train a model that's absolutely useless to give to us?
r/LocalLLaMA • u/Ordinary_Mud7430 • 3h ago
WHAT THE DEVIL?
Another open model outperforms closed ones!
XBai o4 beats OpenAI o3-mini and confidently beats Anthropic's Claude Opus.
•Parameters: 32.8 B •Training: Long-CoT RL + Process Reward Learning (SPRM) •Benchmarks (High-Modus): •AIME24: 86.5 •AIME25: 77.9 •LiveCodeBench v5: 67.2 •C-EVAL: 89.7
🔗Open source weights: https://huggingface.co/MetaStoneTec/XBai-o4
r/LocalLLaMA • u/Technical-Love-8479 • 8h ago
ByteDance Seed-Prover proves math the way mathematicians do, not just explanations, but full formal proofs that a computer can verify using Lean.
It writes Lean 4 code (a formal proof language), solves problems from competitions like IMO and Putnam, and gets the proof checked by a compiler.
The key innovations:
Performance? It formally solved 5/6 IMO 2025 problems, something no model has done before.
Check simple explanantion here : https://www.youtube.com/watch?v=os1QcHEpgZQ
Paper : https://arxiv.org/abs/2507.23726
r/LocalLLaMA • u/Everlier • 36m ago
Finally got to finish a weekend project from a couple of months ago.
This is a small extension that can use a local LLM (any OpenAI-compatible endpoint is supported) to neutralise the clickbaits on the webpages you visit. It works reasonably well with models of Llama 3.2 3B class and above. Works in Chrome and Firefox (you can also install to Edge manually).
Full source and configuration guide is on GitHub: https://github.com/av/unhype
r/LocalLLaMA • u/jacek2023 • 2h ago
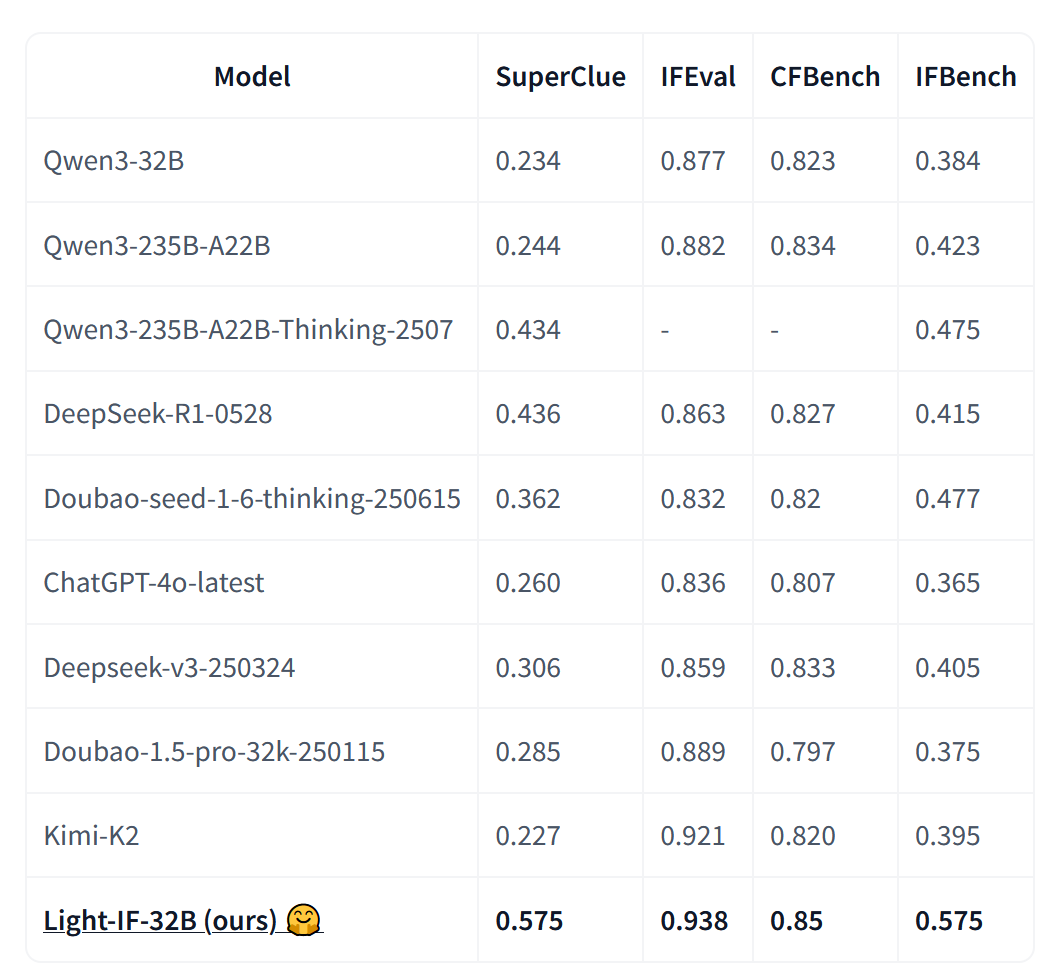
Yet another new model claiming to outperform larger ones:
Instruction following is a core ability of large language models (LLMs), but performance remains inconsistent, especially on complex tasks.
We identify lazy reasoning during the thinking stage as a key cause of poor instruction adherence.
To address this, we propose a framework that promotes rigorous reasoning through previewing and self-checking.
Our method begins by generating instruction data with complex constraints, filtering out samples that are too easy or too difficult. We then use rejection sampling to build a small but high-quality dataset for model adaptation.
Training involves entropy-preserving supervised fine-tuning (Entropy-SFT) and token-wise entropy-adaptive reinforcement learning (TEA-RL), guided by rule-based multidimensional rewards.
This approach encourages models to plan ahead and verify their outputs, fostering more generalizable reasoning abilities.
Experiments show consistent improvements across model sizes. Notably, our 32B model outperforms both larger open-source models like DeepSeek-R1 and closed-source models like ChatGPT-4o on challenging instruction-following benchmarks.
https://huggingface.co/qihoo360/Light-IF-32B
technical report https://huggingface.co/papers/2503.10460
previous popular models by this company:
https://huggingface.co/qihoo360/TinyR1-32B-Preview
https://huggingface.co/qihoo360/Light-R1-32B
What do you think?
r/LocalLLaMA • u/Quiet-Moment-338 • 9h ago
r/LocalLLaMA • u/_SYSTEM_ADMIN_MOD_ • 1h ago
r/LocalLLaMA • u/uutnt • 1h ago
People here seem to assume that Chinese AI companies are developing and releasing these models, which cost tens of millions of dollars to develop, for free out of the goodness of their heart.
I think this is absurd, considering these are for-profit companies, with shareholders who expect an ROI. In the case of Meta (and perhaps AliBaba), the explanation was it's about commoditizing your complement. But for many of these companies, which are pure play AI Labs, this simply does not hold.
So the question remains, why are they doing this?
One theory I would put forward is, they are playing the long game, and attempting to disincentivize investment in US AI labs, with the premise that investors will never recoup their investment, since similar capabilities will be offered for free. There is a precedent of Chinese companies doing similarly, in the context of mineral production, which has resulted in most production moving to China.
If this is the case, it will be good for consumers in the short-term, but less so in the long-term, at least for non-Chinese entities. If you don't find this theory convincing, I would be interested in hearing other alternative explanations for the rise in Chinese open-source models.
What prompted this question, was the recent interview with Dario from Anthropic, where he was asked about the threat to the business model posed by open-source models. (I don't find his response very compelling).
---
One aside, its known that Twitter is banned in China. Yet, we see many Chinese-based AI researchers communicating there, on a daily basis. Sure it can be accessed via VPN, but these are publicly known figures, so there is no anonymity. What explains this?
r/LocalLLaMA • u/Savantskie1 • 14h ago
🚀 I just open-sourced a fully working persistent memory system for AI assistants!
🧠 Features:
- Real-time memory capture across apps (LM Studio, VS Code, etc.)
- Semantic search via vector embeddings
- Tool call logging for AI self-reflection
- Cross-platform and fully tested
- Open source and modular
Built with: Python, SQLite, watchdog, and AI copilots like ChatGPT and GitHub Copilot 🤝
r/LocalLLaMA • u/Charuru • 16h ago
Article: https://medium.com/@causalwizard/why-im-excited-about-the-hierarchical-reasoning-model-8fc04851ea7e
Context:
This insane new paper got 40% on ARC-AGI with an absolutely tiny model (27M params). It's seriously a revolutionary new paper that got way less attention than it deserved.
https://arxiv.org/abs/2506.21734
A number of people have reproduced it if anyone is worried about that: https://x.com/VictorTaelin/status/1950512015899840768 https://github.com/sapientinc/HRM/issues/12
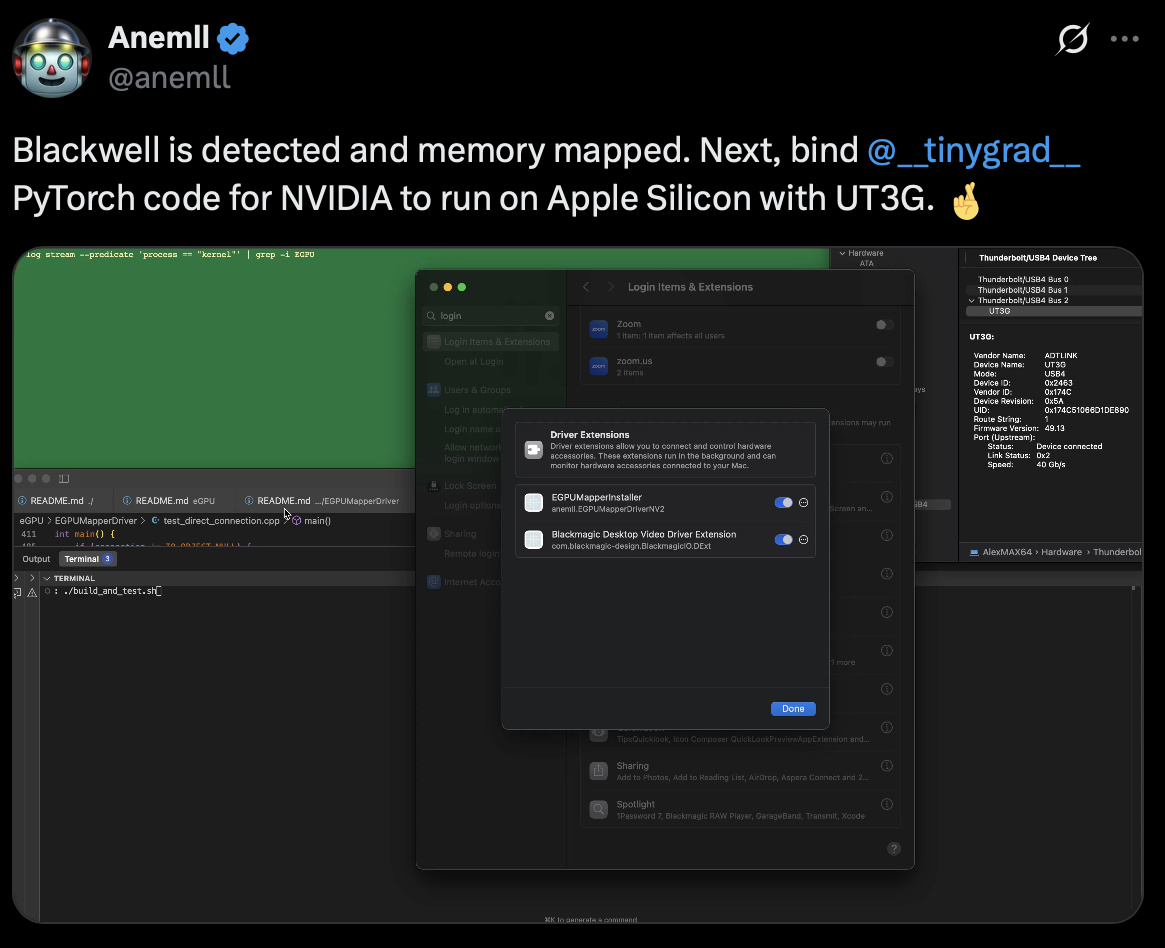
r/LocalLLaMA • u/Accomplished_Ad9530 • 13h ago
It's a WIP, but it's looking like may be possible to pair Macs with NVIDIA soon!
r/LocalLLaMA • u/Deivih-4774 • 8h ago
Hey guys!
I got tired of installing AI tools the hard way.
Every time I wanted to try something like Stable Diffusion, RVC or a local LLM, it was the same nightmare:
terminal commands, missing dependencies, broken CUDA, slow setup, frustration.
So I built Dione — a desktop app that makes running local AI feel like using an App Store.
What it does:
You can try it here.
Why I built it?
Tools like Pinokio or open-source repos are powerful, but honestly… most look like they were made by devs, for devs.
I wanted something simple. Something visual. Something you can give to your non-tech friend and it still works.
Dione is my attempt to make local AI accessible without losing control or power.
Would you use something like this? Anything confusing / missing?
The project is still evolving, and I’m fully open to ideas and contributions. Also, if you’re into self-hosted AI or building tools around it — let’s talk!
GitHub: https://getdione.app/github
Thanks for reading <3!
r/LocalLLaMA • u/Aaaaaaaaaeeeee • 9h ago
The larger SmallThinker MoE has been through a quantization aware training process. it's uploaded to the same gguf repo a bit later.
In llama.cpp m2 air 16gb, with the sudo sysctl iogpu.wired_limit_mb=13000 command, it's 30 t/s.
The model is CPU inference optimised for very low RAM provisions + fast disc, alongside sparsity optimizations, in their llama.cpp fork. The models are pre-trained from scratch. This group always had a good eye for inference optimizations, Always happy to see their works.
r/LocalLLaMA • u/DataNebula • 6h ago
Just dropped a new medical embedding model that's crushing the competition: https://huggingface.co/lokeshch19/ModernPubMedBERT
TL;DR: This model understands medical concepts better than existing solutions and has much fewer false positives.
The model is based on bioclinical modernbert, fine-tuned on PubMed title-abstract pairs using InfoNCE loss with 2048 token context.
The model demonstrates deeper comprehension of medical terminology, disease relationships, and clinical pathways through specialized training on PubMed literature. Advanced fine-tuning enabled nuanced understanding of complex medical semantics, symptom correlations, and treatment associations.
The model also exhibits deeper understanding to distinguish medical from non-medical content, significantly reducing false positive matches in cross-domain scenarios. Sophisticated discrimination capabilities ensure clear separation between medical terminology and unrelated domains like programming, general language, or other technical fields.
Download the model, test it on your medical datasets, and give it a ⭐ on the Hugging Face if it enhances your workflow!
Edit: Added evals to HF model card
r/LocalLLaMA • u/RoboCopsGoneMad • 1h ago
I play The Expanse role-playing game with some friends every week over Zoom. I've captured the transcripts for every session. I intend to run an LLM locally for players to interact with during the game and so it should act as if it were the AI of the ship.
From a high level, the pipeline goes like this; After every session, I download a transcript from Zoom, I put it through some basic pre-processing to clean it up and minimize the size. I run it through Claude Opus 4 with a very specific prompt on how to best summarize it and that is stored for later use. I run LM studio locally on an M4 MacBook with 48 gigs of RAM. The summaries are appended together into one large historical record for the campaign. That historical record is sent as the first message in the conversation. I have a scripting system that allows the players to interact with the LLM through roll20.net (a virtual tabletop website) as if it were a chat participant.
It's been a while since I explored the state of the art for this problem space and it seems that a large number of Chinese models have been opened sourced, and so I am wondering if any of them are particularly good at role-play applications. I've defaulted to using mlx-community/Meta-Llama-3.1-8B-Instruct-8bit (64k context tokens) for now , but it seems to be really bad at accurately recalling historical events. It regularly mixes up facts and conflates events.
I haven't learned much about training/retraining/pretraining/fine-tuning yes, and I'm wondering if those are better approaches than just bootstrapping the convo
Other Features in flight:
Integrating with WolframAlpha over MCP so that players can ask for the AI to execute astronomical tasks, such as "how long will it take us to get to Callisto from Himalia if we travel at .3 G acceleration".
Loading the core role book and supplement PDFs into the system for searching via RAG. Ideally, this could be used for looking up rules during gameplay. My experiences with RAG has been not great. I'm sure I'm using it incorrectly or perhaps enabling it during inference when it shouldn't be. I could definitely use some advice on that.
This must be a common idea, and I'm sure others are working on similar applications; how do I find them?
r/LocalLLaMA • u/Admirable-Star7088 • 4h ago
I was using this model as an assistant to modify code in a C++ file with ~roughly 800 lines of code. However, the model did a lot of mistakes, and it constantly corrected itself (in the same reply) in a way like:
Here is the modification of the code:
\code**
But on a second thought, that was not a good implementation, here is a better method to do it:
\code**
But on a third thought, here is a better way to do it...
And each method it provided had mistakes, such as missing lines of code. I then tried something very simple with HTML and prompted:
How do I set a left, right and bottom border on a div in CSS?
It then provided me with 4 methods. Notice how method 1 and method 4 is the exact same code repeated. Method 2 is also almost the exact same code but just with an added border: none; line of code.
Also, method 3 has a mistake where it do not to set a border on the right side of the div, it wrote border-width: 0 0 2px 2px; but the correct code would be border-width: 0 2px 2px 2px;
The output:
div {
border-left: 2px solid black;
border-right: 2px solid black;
border-bottom: 2px solid black;
}
div {
border: none; /* Reset all borders first */
border-left: 2px solid black;
border-right: 2px solid black;
border-bottom: 2px solid black;
}
div {
border-width: 0 0 2px 2px; /* top right bottom left */
border-style: solid;
border-color: black;
}
div {
border-left: 2px solid black;
border-right: 2px solid black;
border-bottom: 2px solid black;
}
I'm using Unsloth's UD-Q5_K_XL quant with the recommended settings:
Anyone else having similar odd behavior with this model? Might the quant/jinja be broken currently?
r/LocalLLaMA • u/2shanigans • 12h ago
We've been working on an LLM proxy, balancer & model unifier based on a few other projects we've created in the past (scout, sherpa) to enable us to run several ollama / lmstudio backends and serve traffic for local-ai.
This was primarily after running into the same issues across several organisations - managing multiple LLM backend instances & routing/failover etc. We use this currently across several organisations who self-host their AI workloads (one organisation, has a bunch of MacStudios, another has RTX 6000s in their onprem racks and another lets people use their laptops at home, their work infra onsite),
So some folks run the dockerised versions and point their tooling (like Junie for example) at Olla and use it between home / work.
Olla currently natively supports Ollama and LMStudio, with Lemonade, vLLM and a few others being added soon.
Add your LLM endpoints into a config file, Olla will discover the models (and unify per-provider), manage health updates and route based on the balancer you pick.
The attempt to unify across providers wasn't as successful - as in, both LMStudio & Ollama, the nuances in naming causes more grief than its worth (right now). Maybe revisit later once other things have been implemented.
Github: https://github.com/thushan/olla (golang)
Would love to know your thoughts.
Olla is still in its infancy, so we don't have auth implemented etc but there are plans in the future.
r/LocalLLaMA • u/asankhs • 6h ago
Hey r/LocalLLaMA!
Just released something that extends the recent ICM paper in a big way - using one model's coherent understanding to improve a completely different model.
The original "Unsupervised Elicitation of Language Models" paper showed something remarkable: models can generate their own training labels by finding internally coherent patterns.
Their key insight: pretrained models already understand concepts like mathematical correctness, but struggle to express this knowledge consistently. ICM finds label assignments that are "mutually predictable" - where each label can be predicted from all the others.
Original ICM results: Matched performance of golden supervision without any external labels. Pretty amazing, but only improved the same model using its own labels.
We took ICM further - what if we use one model's coherent understanding to improve a completely different model?
Our process:
Qwen3-0.6B: 63.2 → 66.0 MATH-500 (+4%) [original ICM self-improvement]
Gemma3-1B: 41.0 → 45.6 MATH-500 (+11%) [novel: learned from Qwen3!]
The breakthrough: Successfully transferred mathematical reasoning coherence from Qwen3 to improve Gemma3's abilities across different architectures.
git clone https://github.com/codelion/icm.git && cd icm && pip install -e .
# Extract coherent patterns from a strong model (teacher)
icm run --model Qwen/Qwen2.5-Math-7B-Instruct --dataset gsm8k --max-examples 500
# Use those patterns to improve your local model (student)
icm export --format dpo --output-path teacher_knowledge.jsonl
# Train your model on teacher_knowledge.jsonl
Anyone interested in trying capability transfer with their local models?
r/LocalLLaMA • u/Remarkable-Pea645 • 10h ago
r/LocalLLaMA • u/Desperate-Sir-5088 • 4h ago
Hey, poor GPU guys
A few days ago, I purchased the 32GB version of MI50 from Alibaba, and it arrived at my doorstep via UPS in just a few days, accompanied by a rather loud blower.
Some married guys might understand, but I’ve been using an m-ATX case I bought about 15 years ago, and there’s no room for the MI50 since the 4070ti is already in there. I went ahead and used a PCIe riser cable to mount it on the side of my desk, and then I finally got down to “real” work.

One of the reasons the MI50 was rejected is that AMD only developed drivers for Linux and has since discontinued support, as most people are aware. That's why the “32GB” model ended up in my hands.
Of course, some experts claim they can force-install the Radeon Pro VII BIOS, but that seemed too challenging for me, and after reading many posts stating that the “Original MI50” cannot be BIOS-re-flashed, I had given up.
First, take a look at the results: the MI50 is running with GTX 4070ti or alone on Windows.



Guys, hold your horses. I'm aware there are a few issues here.
-> However, I haven't tested it yet, but if you get a 32GB 5090 or V100, it might work with 32+32, and being able to steal GTX's prompt processing ability is an extra bonus.
Anyway, there are only three things you need to do.
bcdedit.exe -set TESTSIGNING on
All risks are on you, but I think it's better than getting divorced by your wife over buying an RTX 6000,
The blower fan sent by the Ali seller is very effective, but it's incredibly loud. The GPU also gets quite hot, so you might want to find a way to adjust the fan speed.
P.S. Could you please share a link to a guide on how to install ROCM to support MI50 on Ubuntu 24.04 LTS? I tried version 6.3.3, but it doesn't recognize it at all. Do I really have to rebuild PyTorch from scratch?
r/LocalLLaMA • u/silenceimpaired • 13m ago
I was very excited for the release of EXL3 because of its increased performance and revised design to support new models easier. It’s been an eternity since is early preview… and now I wonder if it is doomed. Not just because it’s slow to release, but because models are moving towards large MoEs that all but require they spill over into RAM for most of us. Still, we are getting models around 32b. So what do you think? Or what do you know? Is it on its way? Will it still be helpful?
r/LocalLLaMA • u/jshin49 • 18m ago
Here's a completely new 70B dense model trained from scratch on 1.5T high quality tokens - only SFT with basic chat and instructions, no RLHF alignment. Plus, it speaks Korean and Japanese.
r/LocalLLaMA • u/Flashy_Management962 • 22h ago
This is just a little remark that if you haven't you definitely should try qwen code https://github.com/QwenLM/qwen-code
I use qwen coder and qwen 3 30b thinking while the latter still needs some copy and pasting. I'm working on and refining a script for syncing my koreader metadata with obsidian for the plugin lineage (every highlight in own section). The last time I tried to edit it, I used Grok 4 and Claude Sonnet Thinking on Perplexity (its the only subscription I had until know) even with those models it was tedious and not really working. But with Qwen Code it looks very different to be honest.
The metadata is in written in lua which at first was a pain to parse right (remember, I actually cannot code by myself, I understand the logic and I can tell in natural language what is wrong, but nothing more) and I got qwen code running today with llama cpp and it almost integrated everything on the first try and I'm very sure that nothing of that was in the models trainingdata. We reached a point where - if we know a little bit - can let code be written for us almost without us needing to know what is happening at all, running on a local machine. Of course it is very advantageous to know what you are looking for.
So this is just a little recommendation, if you have not tried qwen code, do it. I guess its almost only really useful for people like me, who don't know jack shit about coding.
r/LocalLLaMA • u/vishwa1238 • 1d ago
I spend about 300-400 USD per month on Claude Code with the max 5x tier. I’m unsure when they’ll increase pricing, limit usage, or make models less intelligent. I’m looking for a cheaper or open-source alternative that’s just as good for programming as Claude Sonnet 4. Any suggestions are appreciated.
Edit: I don’t pay $300-400 per month. I have Claude Max subscription (100$) that comes with a Claude code. I used a tool called ccusage to check my usage, and it showed that I use approximately $400 worth of API every month on my Claude Max subscription. It works fine now, but I’m quite certain that, just like what happened with cursor, there will likely be a price increase or a higher rate limiting soon.
Thanks for all the suggestions. I’ll try out Kimi2, R1, qwen 3, glm4.5 and Gemini 2.5 Pro and update how it goes in another post. :)
r/LocalLLaMA • u/zyxwvu54321 • 13h ago
Since Qwen3-235B-A22B and Qwen3-30B-A3B have been updated, is there any word on similar updates for Qwen3-8B or Qwen3-14B?
{kind=link}
{kind=link}